
'%3e%3cpath%20d='M7.99992%2010.6666L10.6666%207.99998M10.6666%207.99998L7.99992%205.33331M10.6666%207.99998H5.33325M14.6666%207.99998C14.6666%2011.6819%2011.6818%2014.6666%207.99992%2014.6666C4.31802%2014.6666%201.33325%2011.6819%201.33325%207.99998C1.33325%204.31808%204.31802%201.33331%207.99992%201.33331C11.6818%201.33331%2014.6666%204.31808%2014.6666%207.99998Z'%20stroke='white'%20stroke-width='1.2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_7301_954'%3e%3crect%20width='16'%20height='16'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)









太初智算·算力服务平台
面向AI创新的一站式智能云服务,提供模型市场、训推一体、算力调度等核心能力,助力企业快速完成AI落地与业务升级。
一云多芯
万卡级自营算力规模,深度适配兼容多元异构算力硬件,提供高吞吐、低延时的极致性价比算力服务。

开放兼容
软件开放,集成主流机器学习、深度学习等人工智能模型开发框架和预训练大模型;硬件兼容,不进行厂家绑定,与软件解耦。

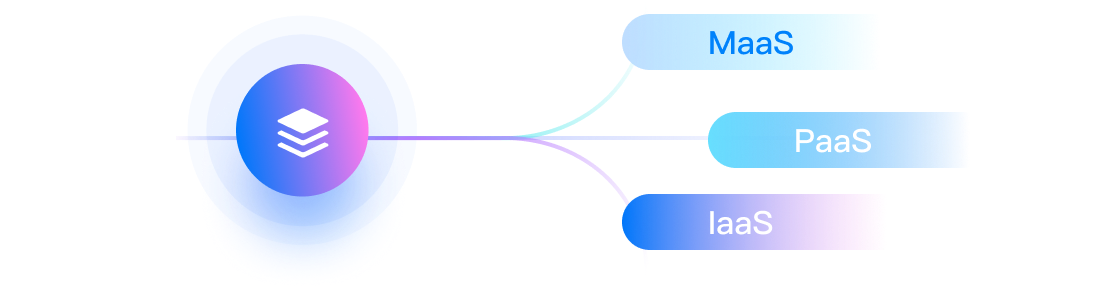
全栈信创
15大类100+全栈信创云服务能力,涵盖laaS,PaaS,MaaS,Al服务等领域。
原生安全
基于云原生,保护AI安全,一体化云原生安全防护。

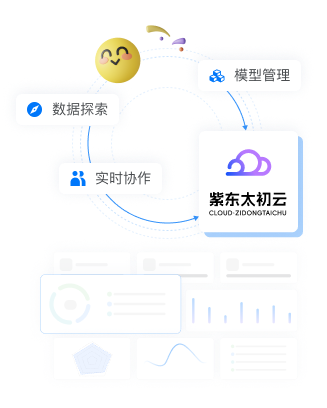
友好易用
一体化全栈式人工智能模型训练和推理平台,构建数据探索、模型管理和实时协作的交互环境。
太初智训·大模型训练推理平台
开箱即用的训练工具链+企业级推理工作台,打造低成本、高可控的模型工厂
太初智享·大模型服务平台
让大模型从实验室走向千行百业,为应用开发者提供高性能、易上手、安全可靠的大模型服务

gpt-oss-20b
GPT-OSS-20B具备210亿参数,每token激活36亿参数,采用MoE(Mixture-of-Experts)架构,专为低延迟、本地化或专业场景设计,仅需 16GB 内存即可在边缘设备(如消费级笔记本电脑或台式机)上运行。GPT-OSS-20B则与o3-mini性能相当,在AIME和HealthBench等测试中表现更佳。

Taichu-LLM
基于海量高质数据训练,具有更强的文本理解、内容创作、对话问答等能力

Qwen3-Reranker-8B
Qwen3 Reranker 8B 模型系列是通义千问家族最新推出的排序任务设计的专属模型。该系列基于Qwen3系列的稠密基座模型,完整继承了基座模型卓越的多语言能力、长文本理解与推理能力。

DeepSeek-R1-0528-Qwen3-8B
将 DeepSeek-R1-0528 的思维链蒸馏出来用于后训练 Qwen3 8B Base,从而获得了 DeepSeek-R1-0528-Qwen3-8B。该模型在 AIME 2024 上的表现达到了开源模型中的最先进水平(SOTA),比Qwen3 8B 高出 +10.0%,并匹配了 Qwen3-235B-thinking 的表现。

ERNIE-4.5-21B-A3B
ERNIE-4.5-21B-A3B 是百度 ERNIE 4.5 系列的文本混合专家(MoE)后训练模型,拥有 210 亿参数,每个 token 激活 30 亿参数。该模型采用异构混合专家架构,在通用语言理解、生成、数学推理和代码生成等方面表现出色。

ChatGLM-6B
智谱AI与清华KEG实验室发布的对话模型,具备强大的推理性能、效果、较低的部署门槛及更长的上下文。
LLaMA3-8B
Llama3是Meta在2024年4月18日公开发布的大型语言模型,Llama3-8B拥有80亿参数,平台支持微调训练。
'%3e%3cpath%20d='M3.86401%205.57332C11.3013%20-3.08134%2025.0933%20-1.37334%2030.248%208.73999H17.8573C15.6253%208.73999%2014.184%208.68932%2012.6227%209.51066C10.788%2010.4773%209.40401%2012.268%208.92001%2014.3707L3.86401%205.57466V5.57332Z'%20fill='%23EA4335'/%3e%3cpath%20d='M10.6774%2015.9999C10.6774%2018.9333%2013.0627%2021.3199%2015.9947%2021.3199C18.928%2021.3199%2021.312%2018.9333%2021.312%2015.9999C21.312%2013.0666%2018.9267%2010.6799%2015.9947%2010.6799C13.0614%2010.6799%2010.6774%2013.0666%2010.6774%2015.9999Z'%20fill='%234285F4'/%3e%3cpath%20d='M18.0586%2022.964C15.0733%2023.8507%2011.5813%2022.8667%209.66797%2019.564C8.20664%2017.044%204.34797%2010.3214%202.59464%207.26538C-3.54803%2016.6787%201.74664%2029.5094%2012.8973%2031.6987L18.0573%2022.964H18.0586Z'%20fill='%2334A853'/%3e%3cpath%20d='M20.9333%2010.68C22.1354%2011.8023%2022.9225%2013.2982%2023.1665%2014.9245C23.4105%2016.5508%2023.0971%2018.2118%2022.2773%2019.6374C21.0093%2021.824%2016.96%2028.6587%2014.9973%2031.968C26.4866%2032.676%2034.864%2021.416%2031.08%2010.6787H20.9333V10.68Z'%20fill='%23FBBC05'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_5160_4731'%3e%3crect%20width='32'%20height='32'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Gemma-2B
Gemma 是 Google 开发的轻量级语言大模型,适合用于各种文本生成任务,能够在资源量较小的端侧设备部署。
Qwen3-Reranker-8B
Qwen3 Reranker 8B 模型系列是通义千问家族最新推出的排序任务设计的专属模型。该系列基于Qwen3系列的稠密基座模型,完整继承了基座模型卓越的多语言能力、长文本理解与推理能力。
三大服务模式满足企业级AI交付
公有云
随启随用
按需计费,减少资源浪费
开箱即用
无需环境配置,5分钟启动AI任务
零运维负担
无需硬件投入,分钟级获取算力
全程护航
7×24小时技术支持,保障业务连续性

私有云
独立部署
独享集群,支持千亿级模型训练
数据隔离
全流程本地化,满足等保/金融级合规
自主可控
适配多种架构,兼容昇腾/海光等国产芯片
软硬一体
开箱即用
硬件预集成,软件预调优,快速部署
性能优化
软硬件协同设计,提升整体运行效率
汇聚行业智慧,驱动企业未来
Agent搭建
高性能搭建助力工作流
全新海量预置模型
丰富智能体编排和编排框架

客户成功案例
"紫东太初"多模态大模型已助力智能汽车、智能制造、智慧医疗、智慧政务等20+个行业模型落地,赋能"人工智能+"应用场景100+个,服务1000+家企业,持续赋能千行百业。